Intro to Rust for JS developers - Part 2
In the first part of this tutorial, we developed a basic CLI capable of parsing user-supplied arguments and validate their format against standard URL structures. It's a good starting point, but simply conforming to a URL format doesn't guarantee the existence or accessibility of the corresponding resource. To address this, we need to perform an HTTP request and ensure it returns a 200 status code.
Coming from Javascript background, a question naturally arises: Does Rust support asynchronous programming in a similar fashion to JavaScript ?
1. Fetch an URL: async/await
In fact, Rust doe support async programming through the async/await syntax. The fundamental building block of it is the Future. A Future is a value that represents a computation that might not be finished yet. Think of it as a promise in JavaScript.
Async functions are called like any other Rust function. However, calling these functions does not result in the function body executing. Instead, calling an async fn returns a value representing the operation. To actually run the operation, you should use the .await operator on the return value.
async fn my_async_func() {
// Some async processing
}
// No function body executing here
let future = my_async_func();
// Execution happens here
let res = future.await?;
The fancy syntax .await? may surprise you but don't worry, we will talk about it in a moment.
An async fn is used to enter an asynchronous context. However, asynchronous functions must be executed by a runtime. The runtime contains the asynchronous task scheduler, provides evented I/O, timers, etc. Unless JavaScript, No built-in runtime is provided by Rust. Instead, runtimes are provided by community maintained crates.
This is where an async runtime like Tokio comes into play.
So, to be able to make an async HTTP request we will need to add the tokio Crate:
cargo add tokio --features "full"
The --features flag in Cargo is used to enable specific features for a Rust crate. The Tokio crate in Rust provides several feature flags that can be enabled based on specific requirements. full: Enables all features except test-util and tracing(doc).
The runtime does not automatically start, so the main function needs to start it. The attribute macro #[tokio::main] provided by tokio crate transforms the main function into an asynchronous entry point of the program:
use tokio;
#[tokio::main]
async fn main() {
// we can now make an asyn HTTP request
}
HTTP request
The reqwest crate provides a convenient, higher-level HTTP Client to make http requests. Let's add it:
cargo add reqwest
To use reqwest we need to change the signature of the main function because calling reqwest::get return a Result type. The Result type in Rust is an enum used for error handling. It represents a type that can have one of two outcomes: Ok(T) indicating a successful result, or Err(E) indicating an error. Here, T is the type of the successful value, and E is the type of the error.
enum Result<T, E> {
Ok(T),
Err(E),
}
In our case the return type is : Result<(), reqwest::Error>
reqwest::Error: This is the error type that the function might return. In this context, it indicates that the function may return an error related to thereqwestHTTP client operations.()Called the unit type, is a type that has exactly one value, and is used when there is no other meaningful value that could be returned. It is similar tovoidin other languages.
use tokio;
#[tokio::main]
async fn main() -> Result<(), reqwest::Error> {
let url = "http://example.com";
let response = reqwest::get(url).await?;
let body = response.text().await?;
println!("Response: {}", body);
Ok(()) // No ";" at the end to make it a returned value
}
At the end of the function, Ok(()) is returned. This indicates a successful execution of the function without any meaningful value to return.
Let's get back to the fancy syntax .await?:
When you see .await? used together, it means that the future being awaited is expected to return a Result type.
The .await part pauses the function execution until the future resolves, and once the future resolves, the ? operator checks the Result.
If the future resolves to an Err, the ? operator will return that error from the current function.
If the future resolves to an Ok, the value inside the Ok is extracted and can be used in subsequent code.
Let's continue building our CLI and add a function fetch_url . This function calls an url and display it's response content is it succeed or the error message if it fails:
use std::env::args;
use url::Url;
use tokio;
use reqwest;
fn is_valid_url(url: &str) -> bool {
let result = Url::parse(url);
result.is_ok() // Without ; at end, the value is returned automatically. It's a shorthand for return result.is_ok();
}
async fn fetch_url(url: &str) {
println!("Fetching URL {} in progress...", url);
let response = reqwest::get(url).await;
match response {
Ok(res) => {
println!("✅ Succeeded!");
let url_content = res.text().await;
print!("{:?}", url_content);
}
Err(e) => {
println!("❌ Failed: {}",e.to_string() );
}
}
}
#[tokio::main]
async fn main() -> Result<(), reqwest::Error> {
let args: Vec<String> = args().collect();
println!("Audiofy: Transform your favorites articles to a podcast 🚀");
for (index, arg) in args.iter().skip(1).enumerate() {
if is_valid_url(arg) {
fetch_url(arg).await; // without .await, func body will not be executed
} else {
println!("- Invalid argument at index {}: {}", index, arg);
}
}
Ok(())
}
Pattern matching
Pattern matching in Rust is a powerful way to check a value against a series of patterns and then execute code based on which pattern matches.
It's like a more advanced version of a switch-case statement. In our implementation, pattern matching is used with the match statement to handle the Result type returned by a network request.
Let's break down the example in fetch_url:
match response { ... }: This line starts the pattern matching operation on theresponsevariable.responseis aResulttype, which means it can be eitherOk(indicating success) and containing a value, orErr(indicating an error) and containing an error description.Ok(res) => { ... }: This is the first pattern. IfresponseisOk, it means the request was successful. TheresinsideOk(res)is a variable that holds the successful value returned by the request. The corresponding block of code within{ ... }is executed in this case.Err(e) => { ... }: This is the second pattern. IfresponseisErr, it means there was an error with the request. TheeinsideErr(e)is a variable that holds the error information. The corresponding block of code within{ ... }is executed in this case.
Let's test both scenarios, with a valid URL and a fake one:
cargo run https://www.sadry.dev/articles/intro-to-rust-for-js-devs-part-1
// Output
Audiofy: Transform your favorites articles to a podcast 🚀
Fetching URL https://www.sadry.dev/articles/intro-to-rust-for-js-devs-part-1 in progress...
✅ Succeeded!
Ok("<!DOCTYPE html><html lang=\"en\" class=\"h-full antialiased\">
// ... some unreadeable HTML
null\\n\"])</script></body></html>")%
cargo run http://foo.lol
// Output
Audiofy: Transform your favorites articles to a podcast 🚀
Fetching URL http://foo.lol in progress...
❌ Failed: error sending request for url (http://foo.lol/): error trying to connect: dns error: failed to lookup address information: nodename nor servname provided, or not known
2. Parse HTML: Ownership model
To get the content from the URL we will a crate called scraper. It provides functionality to parse HTML documents and extract data from them using CSS selectors.
cargo add scraper
Let's implement a parse_html function that get the h1 tag and display it to the console (doc):
the method parse_document taks a reference to a string &str and
fn parse_html(html: &str) {
// Parse the HTML
let document = Html::parse_document(html);
// Create a CSS selector
let h1_selector = Selector::parse("h1").unwrap();
// Get the h1 node content
let h1 = document.select(&h1_selector).next().unwrap();
let text = h1.text().collect::<Vec<_>>();
println!("{:?}", text);
}
And now let's call it inside the function fetch_url:
async fn fetch_url(url: &str) {
println!("Fetching URL {} in progress...", url);
let response = reqwest::get(url).await;
match response {
Ok(res) => {
let url_body = res.text().await;
match url_body {
Ok(html) => {
println!("✅ Succeeded!");
parse_html(&html); // Passing html instead of &html will cause a compilation error
}
Err(e) => {
println!("❌ Failed to get URL body: {}", e.to_string())
}
}
}
Err(e) => {
println!("❌ Failed to fetch URL: {}", e.to_string());
}
Why parse_html(html) does not work and &html works?
There is an interesting point in this code, mainly in this line parse_html(&html).
If you try to pass html instead of &html the compiler will yell at you saying mismatched types and consider borrowing here: &. What does it even mean?
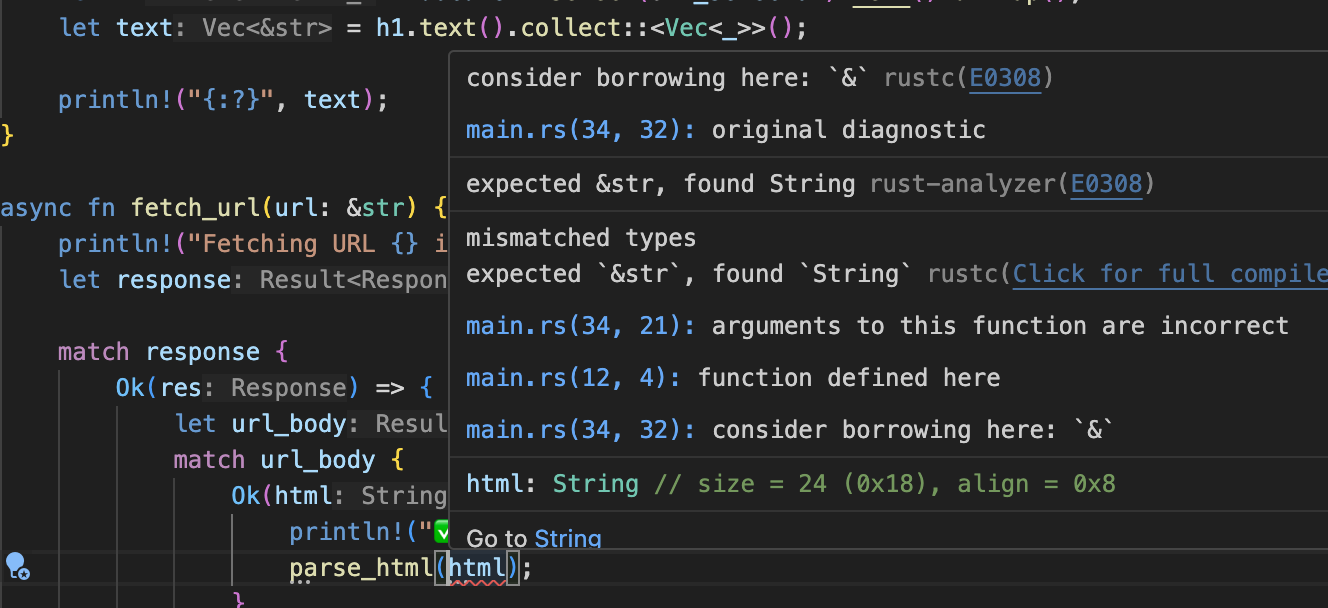
In Rust, the difference between passing html and &html to a function lies in ownership and borrowing, which are key concepts in Rust's memory management system.
Ownership
The concept of ownership means each piece of data can only have one owner. When you assign a variable to another or pass it to a function, the original variable can no longer access the data. This transfer is called "moving".
let x = String::from("hello"); // x owns the string
let y = x; // Ownership is moved to y
// x is no longer valid here
Ownership can be transferred. For example, when you pass a variable to a function, the function becomes the new owner of that variable's data. When the owner (a variable) goes out of scope, its data is automatically cleaned up. This helps prevent memory leaks.
Borrowing
Borrowing is like asking permission to use someone else's data temporarily. It is done through references. You create a reference to data by using the & symbol.
By default, references are immutable. This means you can't modify the borrowed data.
let x = String::from("hello");
let y = &x; // y borrows x
println!("{}", y); // You can use y
// x is still valid and usable here
You can create a mutable reference with &mut, but you can only have one mutable reference to a particular piece of data in a particular scope. This prevents data races.
While a reference to data exists, the data cannot be moved or go out of scope. This prevents dangling references.
In summary:
- Ownership ensures that each piece of data has a single owner, which is responsible for cleaning up the data. It prevents memory leaks and other memory-related problems.
- Borrowing allows you to use data owned by another variable without taking ownership. It ensures safety by preventing data races and dangling references.
These concepts are fundamental to Rust's memory safety guarantees, eliminating many common bugs found in other languages related to memory management and concurrency.
3. To be continued
While our CLI is operational, its current implementation leaves much to be desired. The codebase lives in a single file, suffers from nested pattern matching and an inefficient structure where parsing function is embedded within fetching function. To elevate our code to a professional standard, a refactoring is necessary. This will involve modularizing the code for a better separation of concerns. This woulb be our task for the next article.